

伏雨朝寒悉不胜,那能还傍杏花行。去年高摘斗轻盈。漫惹炉烟双袖紫,空将酒晕一衫青。人间何处问多情。 ———— 纳兰容若
CLOUD

 虽然说之前已经在shadertoy里面实现过一遍云了,但是没有特别的深印象,这次做云更加深入理解了当时的ray marching的步骤,也对云渲染有了更深的理解,这里就不标unity了,因为更偏向图形和渲染,那就开个新tag图形学吧!先来说说云的光照问题解决。
虽然说之前已经在shadertoy里面实现过一遍云了,但是没有特别的深印象,这次做云更加深入理解了当时的ray marching的步骤,也对云渲染有了更深的理解,这里就不标unity了,因为更偏向图形和渲染,那就开个新tag图形学吧!先来说说云的光照问题解决。
一篇论文
早在2001年,Mark J. Harris and Anselmo Lastra就实现了这个过程。论文在文末有引用可以自行跳转。然后我仔细得看完之后,发现虽然让我对云的渲染有了更深入的理解,但并没有解决marching性能的问题,我要做的是骗子云,和这个也没啥关系。下面展开讲讲这篇文章。
这是一张很牛的文章截图。
 经过云到眼睛里光的总量是from direction l that is not absorbed by intervening particles, plus light scattered to P from other particles。翻译过来就是直射光和散射光,之前的Raymarching也提到了这件事(想到面试的时候被问到这个居然没答上来也是悔恨万分)。吸收较为简单,根据Beer-Lambert公式,也就是这个公式里面的光学深度,它是最重要的体积内部的传播公式,
经过云到眼睛里光的总量是from direction l that is not absorbed by intervening particles, plus light scattered to P from other particles。翻译过来就是直射光和散射光,之前的Raymarching也提到了这件事(想到面试的时候被问到这个居然没答上来也是悔恨万分)。吸收较为简单,根据Beer-Lambert公式,也就是这个公式里面的光学深度,它是最重要的体积内部的传播公式,e^-∫τ dt。当然在这里需要离散化计算积分。
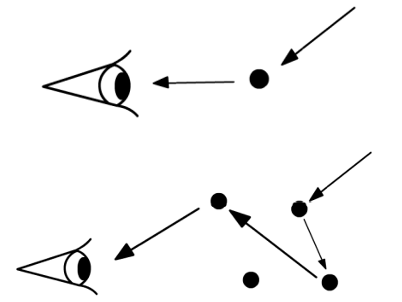
云进入到我们眼睛里其实是一个多次散射的过程,这个图显示的就是单次和多次散射的区别(single/multiple scattering model)当然云的计算就得采用后者会更加真实多次散射就离不开相位函数,这是一个形容光在在这个地方出现的概率——这里我们用的是瑞利散射的trick(这个是用来估算空气散射的)。散射的光有3/16Π (1 + cos^2 θ)概率出现(俺也不知道为什么这里写的3/4,因为伪代码里面也除多了一个4Π。当然这个公式实际上更复杂,和波长都有关系,不过在实时计算中可以理解为一个常数,推导见大佬,跳转。所以我们计算云的光照的时候两个部分,散射可以理解为就是光的入射——能量损耗——出射计算相位函数。透射就是背景光(图像)被视线方向厚度阻挡的程度(其实也是散射只是这里因为本来就弱,其他方向带来的几乎没有)。
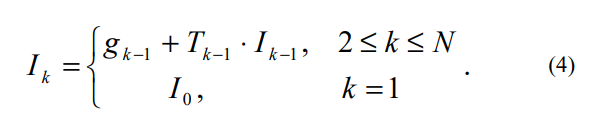 在这里我就已经觉得不对了——为什么imposter还是raymarching感觉的离散化?然后看到了伪代码。大概的过程就是光拍一张厚度作为离线,人眼拍一张厚度作为实时的,拿出像素对应到的那部分粒子,再根据距离排序这些粒子,然后开始类似MARCH的行为!!(只是这里是each particle)整个计算分为两部分。预计算和实时计算,它的impostor只是说它用了那个面片代表一团云的trick技术,而非我们现在说的拍一堆角度的那个。它更像是我们普遍意义的billboard。
在这里我就已经觉得不对了——为什么imposter还是raymarching感觉的离散化?然后看到了伪代码。大概的过程就是光拍一张厚度作为离线,人眼拍一张厚度作为实时的,拿出像素对应到的那部分粒子,再根据距离排序这些粒子,然后开始类似MARCH的行为!!(只是这里是each particle)整个计算分为两部分。预计算和实时计算,它的impostor只是说它用了那个面片代表一团云的trick技术,而非我们现在说的拍一堆角度的那个。它更像是我们普遍意义的billboard。

预计算部分
第一段是计算有云的那部分像素单独拎出来做march,把云作为粒子计算,一个粒子只作为一次散射,然后每一次散射的color都会加入到最后的成像中。Albedo τ light * solid angle(感觉是用类似视锥角度来找到需要bake的那些像素。)然后赋值给 color,alpha存入τ,(这个如果不均匀可以实现内部的密度变化?)
实时计算部分
还是Sort完之后计算phase之后的光照color(有角度的存在)然后一个个用alpha blend上这些算出结果
问题:显然每次变换光源都要重新计算。每次用imposter记录下来预计算的灯光信息。 文章后面的就完全是一些其他的trick了,包括穿插问题,impostor的性能优化之类的,(比如远的隔帧渲染)就不多赘述,或许到后面我有时间实现体积云的时候抄抄大表哥的优化策略。显然这个方法并不能做我需要的“低消耗billboard云"。
光照解决方案
当然,在这里,我们的骗子云似乎还没有找到合适的光照解决方案,然后我看到了一个叫六向光照图的东西,就是给这团云拍6向光照,然后使用的时候混合。
To render this we simply render lights and shadows from a Light that’s tangently positioned to the camera. You can do it all in 1 pass if you are a Houdini guru but to put it simply you can do it in 2 passes: Red Light Top + Green Light Bottom, render. Red light Right + Green Light Left, render. Combine them in photoshop in a single RGBA texture. From there, all you need is to unpack it and mix it in the shader. Here’s the shader code I am currently using:
到这里,很trick,但是也费,如果我用的16pic的图,我每一个角度都用六向光图来解决么?这似乎在内存上就不太合理,如果只是一个公告牌,那确实没问题。但问题是现在我们还会飞,云的上面得看到。后来想着反正我都有法线有深度,那就按正常trick云来吧。在知乎上看到了杨超大佬分享的文章,遗憾在光照那一part被删掉了(https://zhuanlan.zhihu.com/p/386314798)于是只好自己开始乱试。看到了乐乐女神在知乎的一篇回答摸瓜到了[The Witness做的云光照]8然后大刀阔斧改了一下——本来是一个插片云的方案,加入了次表面的背光常数。最终勉强算是把光照解决得还行。
//float noise = tex2D(_Noisemap, i.uvs + _Time.y);
float lthick = baseTex.a ;
float thickness = 1 - exp(-5 * lthick );
color.a = saturate(thickness * 1.2 * dis); ;
float a = 0.33;
float edgeatten =10;
float forward_scattering = exp(-7 * lthick );
forward_scattering = pow(forward_scattering, saturate(_atten * (0.95 + dot(viewdir, lightdir)))) ;
float3 H = lightdir + Normal * a;
float phaselight = (1 + VL * VL );
float sss = saturate(dot(viewdir,-H));
float spe = pow(sss, edgeatten) * (1.1- thickness);
//float3 ambient =pow ((1-lthick),0.2 )* 0.3 ;
float3 backlight = spe* 1.3 * _LightColor0 ;
forward_scattering *= saturate(1.45 - abs(dot(Normal,lightdir))) ;
float3 directlight = NL * _LightColor0 * 0.8 ;
//float3 scatter = _TintColor * smoothstep(pow(1-thickness,0.6),0,0.05) / 4 / 3.14 * 4;
//color.rgb = 0.25 * _Ambientcolor * (1.5-NL) + forward_scattering * 0.9 ;
color.rgb = forward_scattering + directlight + 0.45 * _Ambientcolor * (1.5-NL)*(1- forward_scattering) + backlight;Impostor计算方法
Imposter的计算方法在上一篇文章里面讲过了具体的数学细节,可以到博客里去找一下。上次提到了ONV,核心原因是这是最好的impostor办法,因为如果直接的经纬线会导致球上部的精度下降,所以Octahedron是很好的存图的办法。最终这个过程基本的思路就是找到三张图,然后根据视角和对应角度的差值来混合三张图,最后加入一个视差映射来进行对应每一张图的变形拉伸。思路代码: 大概的代码中文翻译过来解释就是:
--
1、首先修正一个大uv称为grid,找到viewdir对应的uv,
2、OCN找到采样向量以及周围最近的三个frame,然后重新根据frame的整数uv重构出法线(逆OCN),
3、对于任一texcoord求到摄像机和单位球面的小三角的交点,先求出小菱形的x和z在模型空间的向量,然后算出交点的uv( virtual plane uv)。
4、得到了三组uv,和三组frame在x和z方向的向量。存入frame
--
1、根据三组uvfrac 得到grid,floor得到frame,并求到新的frame(整数uv),和原来的uv(个体uv)相加,得到可以在图上准确采样的uv,三次结合视差对图进行采样,然后混合权重。
--贴一个主要函数的代码
inline void OctaImpostorVertex( inout ImposterData imp )
{
// Inputs
float2 uvOffset = _AI_SizeOffset.zw;
float parallax = -_Parallax; // check sign later
float UVscale = _ImpostorSize;
float framesXY = _Frames;
float prevFrame = framesXY - 1;
float3 fractions = 1.0 / float3( framesXY, prevFrame, UVscale );
float fractionsFrame = fractions.x;
float fractionsPrevFrame = fractions.y;
float fractionsUVscale = fractions.z;
// Basic data
float3 worldOrigin = 0;
float4 perspective = float4( 0, 0, 0, 1 );
//float3 worldCameraPos = worldOrigin + mul( UNITY_MATRIX_I_V, perspective ).xyz;
float3 worldCameraPos = _WorldSpaceCameraPos;
float3 objectCameraPosition = mul( ai_WorldToObject, float4( worldCameraPos, 1 ) ).xyz - _Offset.xyz; //ray origin
float3 objectCameraDirection = normalize( objectCameraPosition );
// Create orthogonal vectors to define the billboard
float3 upVector = float3( 0,1,0 );
float3 objectHorizontalVector = normalize( cross( objectCameraDirection, upVector ) );
float3 objectVerticalVector = cross( objectHorizontalVector, objectCameraDirection );
// Billboard
float2 uvExpansion = imp.vertex.xy;//obj space,本来平均分的四个象限顶点就会被变换到billboard的位置
float3 billboard = objectHorizontalVector * uvExpansion.x + objectVerticalVector * uvExpansion.y;
float3 localDir = billboard - objectCameraPosition; // ray direction 后续相当于插值为任意的ray
// Octahedron Frame
float2 frameOcta = VectortoOctahedron( objectCameraDirection.xzy ) * 0.5 + 0.5;
// Setup for octahedron
float2 prevOctaFrame = frameOcta * prevFrame;//frame的具体数字
float2 baseOctaFrame = floor( prevOctaFrame );//frame的整数
float2 fractionOctaFrame = ( baseOctaFrame * fractionsFrame );//整数frame在整张贴图的uv位置(归零)
// Octa 1
float2 octaFrame1 = ( baseOctaFrame * fractionsPrevFrame ) * 2.0 - 1.0;//将uv重新映射回-1到1
float3 octa1WorldY = OctahedronToVector( octaFrame1 ).xzy;//重构回世界的向量,并且交换zy轴?? 或者我可以理解为叉乘么?
float3 octa1LocalY;
float2 uvFrame1;
RayPlaneIntersectionUV( octa1WorldY, objectCameraPosition, localDir, /*inout*/ uvFrame1, /*inout*/ octa1LocalY );
//因为normal不是相机空间完整的y(有3frame)所以这里localy是octa的camera space normal是乘上了parallax,得到的就是采样原图的基础偏移向量parallax1
//但这里的parallax不是针对pom的,而是针对frame采样上的
float2 uvParallax1 = octa1LocalY.xy * fractionsFrame * parallax / octa1LocalY.z; // octa1LocalY.xy = viewDir.xy / viewDir.z
uvFrame1 = ( uvFrame1 * fractionsUVscale + 0.5 ) * fractionsFrame + fractionOctaFrame;// for converting the parallax into 0-1 (originally -0.5-0.5) then find the all count
imp.uvsFrame1 = float4( uvParallax1, uvFrame1) - float4( 0, 0, uvOffset );
// Octa 2
float2 fractPrevOctaFrame = frac( prevOctaFrame );//frame的小数,是具体uv
float2 cornerDifference = lerp( float2( 0,1 ) , float2( 1,0 ) , saturate( ceil( ( fractPrevOctaFrame.x - fractPrevOctaFrame.y ) ) ));
float2 octaFrame2 = ( ( baseOctaFrame + cornerDifference ) * fractionsPrevFrame ) * 2.0 - 1.0;
float3 octa2WorldY = OctahedronToVector( octaFrame2 ).xzy;
float3 octa2LocalY;
float2 uvFrame2;
RayPlaneIntersectionUV( octa2WorldY, objectCameraPosition, localDir, /*inout*/ uvFrame2, /*inout*/ octa2LocalY );
float2 uvParallax2 = octa2LocalY.xy * fractionsFrame * parallax / octa2LocalY.z;
uvFrame2 = ( uvFrame2 * fractionsUVscale + 0.5 ) * fractionsFrame + ( ( cornerDifference * fractionsFrame ) + fractionOctaFrame );
imp.uvsFrame2 = float4( uvParallax2, uvFrame2) - float4( 0, 0, uvOffset );
// Octa 3
float2 octaFrame3 = ( ( baseOctaFrame + 1 ) * fractionsPrevFrame ) * 2.0 - 1.0;
float3 octa3WorldY = OctahedronToVector( octaFrame3 ).xzy;
float3 octa3LocalY;
float2 uvFrame3;
RayPlaneIntersectionUV( octa3WorldY, objectCameraPosition, localDir, /*inout*/ uvFrame3, /*inout*/ octa3LocalY );
float2 uvParallax3 = octa3LocalY.xy * fractionsFrame * parallax / octa3LocalY.z;
uvFrame3 = ( uvFrame3 * fractionsUVscale + 0.5 ) * fractionsFrame + ( fractionOctaFrame + fractionsFrame );
imp.uvsFrame3 = float4( uvParallax3, uvFrame3) - float4( 0, 0, uvOffset );
imp.octaFrame = 0;
imp.octaFrame.xy = prevOctaFrame;
imp.vertex.xyz = billboard + _Offset.xyz;
imp.normal.xyz = objectCameraDirection;
imp.viewPos.xyz = UnityObjectToViewPos( imp.vertex.xyz );
}然后在frag里面采样的步骤可以用下面的
inline void OctaImpostorFragment(in ImposterData imp,inout half3 Normal, inout float4 clipPos, inout float3 worldPos,inout half4 baseTex )
{
float depthBias = -1.0;
float textureBias = _TextureBias;
// Weights
float2 fraction = frac( imp.octaFrame.xy );
float2 invFraction = 1 - fraction;
float3 weights;
weights.x = min( invFraction.x, invFraction.y );
weights.y = abs( fraction.x - fraction.y );
weights.z = min( fraction.x, fraction.y );
//using zw to sample the depth,the real pom here
//0-1 ~ -0.5 0.5
/*
float4 parallaxSample1 = tex2Dbias( _Normals, float4( imp.uvsFrame1.zw, 0, depthBias) );
float2 parallax1 = (( 0.5 - parallaxSample1.a ) * imp.uvsFrame1.xy ) + imp.uvsFrame1.zw;
float4 parallaxSample2 = tex2Dbias( _Normals, float4( imp.uvsFrame2.zw, 0, depthBias) );
float2 parallax2 = ( ( 0.5 - parallaxSample2.a ) * imp.uvsFrame2.xy ) + imp.uvsFrame2.zw;
float4 parallaxSample3 = tex2Dbias( _Normals, float4( imp.uvsFrame3.zw, 0, depthBias) );
float2 parallax3 = ( ( 0.5 - parallaxSample3.a ) * imp.uvsFrame3.xy ) + imp.uvsFrame3.zw;
*/
float depth1, depth2, depth3;
float2 parallax1 = ParallaxMapping(imp.uvsFrame1, depth1);
float2 parallax2 = ParallaxMapping(imp.uvsFrame2, depth2);
float2 parallax3 = ParallaxMapping(imp.uvsFrame3, depth3);
// albedo alpha
float4 albedo1 = tex2Dbias( _Albedo, float4( parallax1, 0, textureBias) );
float4 albedo2 = tex2Dbias( _Albedo, float4( parallax2, 0, textureBias) );
float4 albedo3 = tex2Dbias( _Albedo, float4( parallax3, 0, textureBias) );
float4 blendedAlbedo = albedo1 * weights.x + albedo2 * weights.y + albedo3 * weights.z;
baseTex.rgb = blendedAlbedo.rgb;
// early clip
baseTex.a = saturate( blendedAlbedo.r - _ClipMask);
// normal depth
float4 normals1 = tex2Dbias( _Normals, float4( parallax1, 0, textureBias) );
float4 normals2 = tex2Dbias( _Normals, float4( parallax2, 0, textureBias) );
float4 normals3 = tex2Dbias( _Normals, float4( parallax3, 0, textureBias) );
float4 blendedNormal = normals1 * weights.x + normals2 * weights.y + normals3 * weights.z;
//float3 localNormal = blendedNormal.rgb * 2.0 - 1.0;
//localNormal = float3(localNormal.x,localNormal.y,localNormal.z);
float3 localNormal = blendedNormal.rgb
;
//float3 worldNormal = UnityObjectToWorldNormal( localNormal);
Normal = localNormal;
float3 viewPos = imp.viewPos.xyz;
float depthOffset = ( ( depth1 * weights.x + depth2 * weights.y + depth3 * weights.z ) - 0.5 /** 2.0 - 1.0*/ ) /** 0.5*/ * _DepthSize * length( ai_ObjectToWorld[ 2 ].xyz );
// else add offset normally
viewPos.z += depthOffset;
worldPos = mul( UNITY_MATRIX_I_V, float4( viewPos.xyz, 1 ) ).xyz;
clipPos = mul( UNITY_MATRIX_P, float4( viewPos, 1 ) );
clipPos.xyz /= clipPos.w;
if( UNITY_NEAR_CLIP_VALUE < 0 )
clipPos = clipPos * 0.5 + 0.5;
}视差所需要的深度图可以存在Normal的A通道里面。一开始我认为抖动是由于我的视差不到位产生的,后来发现并不是,我从原来单次采样的视差算法变成了steep pararllax 多采样了五六次,最终抖动减缓的效果依然有限。Houdini的impostor相机工具为我们提供了很便捷的图片生成方式,但是需要注意yz轴在unity里面需要调整一下。
然后这一朵还算流畅的云,就通过这两张图实现了!当然,这里是有硬伤的,就是云不是树,异质化太强,而这个只能做有限款的云,而且在相交的地方很难融合,当然如果用延迟渲染拿gbuffer里面的图做点什么处理或许有可能实现,但是很麻烦,导致如果是用这个渲染的天空其实还挺出戏的,都是一团团的,然后就是图的分辨率限制了图的精细程度,现在一张2048的图每一个frame长边只有不到100像素,再多也就两百左右的像素,所以精度很低,impostor的原生问题是靠近看了之后就会抖动严重,而且用这个方法去渲染边边的动态也不好搞,加了效果很一般。那么这团云能干嘛呢?我觉得主要是可以自定义形状并且不像billboard那么固定,可能比较适合远山又不是那么远的山的那团特殊的云?或者无视抖动的土地云?
上面的两个图都是没开任何后处理的raw效果,开了可能更好一点。不过想起来的时候已经录完了,算了就这样吧~ 最后看到了杨超大佬在知乎发的那个云在游戏中的成品应用,吃鸡游戏的低空云以及荒野的召唤里的Sprite云,感觉就是:imposter干啥,完全没必要。。(上面的那个shader也稍微参考了一下超哥翻译的代码)。再抬头看看天空的云,多数时候,这天上的云还真的没有体积感——面片挺好的。
参考
https://realtimevfx.com/t/smoke-lighting-and-texture-re-usability-in-skull-bones/5339 Mark J. Harris and Anselmo Lastra, Real-Time Cloud Rendering. Computer Graphics Forum (Eurographics 2001 Proceedings), 20(3):76-84, September2001. [PDF] http://ma-yidong.com/2020/12/27/game-art-trick-light-field-and-imposter/ 以及偶然发现了一个和我一样转行的学长的个人博客,他也研究了云哈哈。他还研究了球谐函数来实现存储。 https://lab.uwa4d.com/lab/5b3e2362d6d8c0171a943d87 大佬的开源impostor算法源码 Unity asset store Amplify impostor
作者: Ayse
nvmolminkm2024-11-26 07:55
《来来往往》国产剧高清在线免费观看:https://www.jgz518.com/xingkong/30837.html
nqjvogfyek2024-11-29 08:09
《人民英雄国语》剧情片高清在线免费观看:https://www.jgz518.com/xingkong/130207.html
upvcbcaglv2024-12-06 07:56
《人民英雄国语》剧情片高清在线免费观看:https://www.jgz518.com/xingkong/130207.html
jhyiydiogv2024-12-06 13:32
《我本善良》香港剧高清在线免费观看:https://www.jgz518.com/xingkong/141295.html
bortzzeddo2024-12-09 06:06
《压力之下:美国女足世界杯队》记录片高清在线免费观看:https://www.jgz518.com/xingkong/20551.html